一、给定的是列表页采集
以采集新浪文章为例:
1、添加节点;
2、选择要增加采集的栏目;
3、在节点名称框里起个名字,然后把要采集的新浪各地新闻列表地址copy过来:


4、下来发现好多选项,如“采集页面地址方式二,内容页地址前缀…”先不要理他,后面再一一详解,直接拉到 “信息链接区域正则”;
5、设置采集的列表信息链接区域正则,我们点击查看新浪各地新闻列表“源文件”:


6、得到信息链接区域正则:

7、得到信息页链接正则:

8、注意:如果信息页链接是相对地址,例如: 那么“内容页地址前缀”要加域名
![]()
9、现在要采集内容页的标题和内容

10、取得标题正则:

11、取得新闻内容正则:

(注意:新闻内容正则里的 d_id=’*’ 用了通配符,因为每一篇新闻的d_id值是不同的,所以可以用*来代替它,“*”可以代替任意字符。)
点击提交按钮就完成了整个采集节点:
12、预览采集节点是否正确




预览采集节点无误后,然后返回“管理节点”,点击“开始采集”链接就开始进行采集。
二、直接采集内容页面
1、在“栏目”选项下,选择左侧菜单“采集管理”-“采集管理节点(分页)”,点击“增加节点”;
2、选择要增加采集的栏目;

3、接下来最重要的就是对采集的规则进行设定:
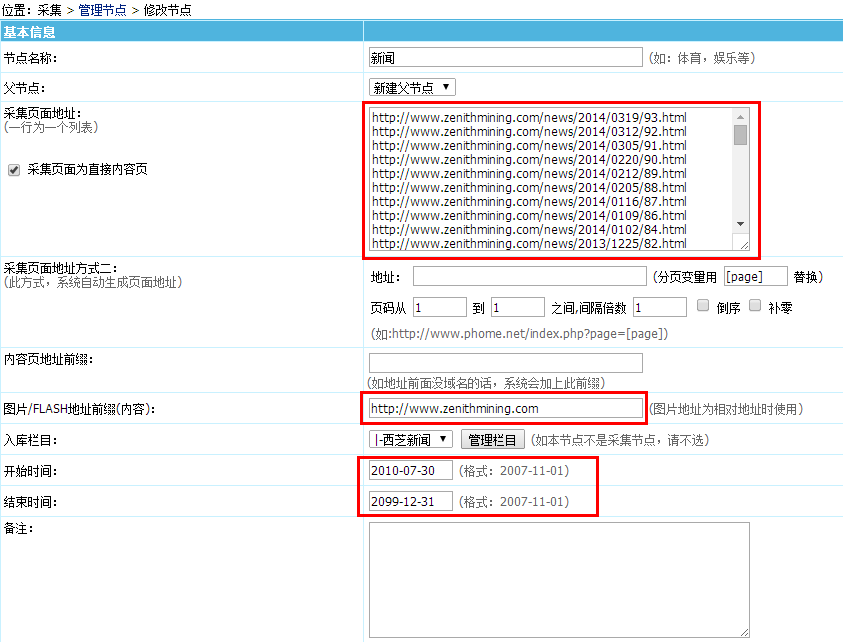
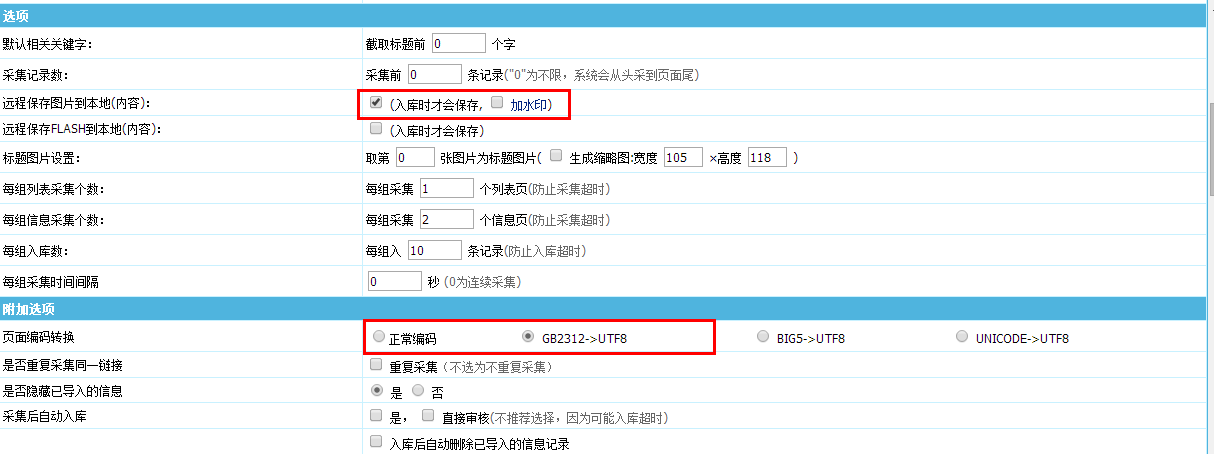
“附加选项”-“页面编码转换”,这里设定的是页面的编码,如果原来的页面是编码为gb2312,采集后要转为utf-8的话,要选择“GB2312->UTF8”;
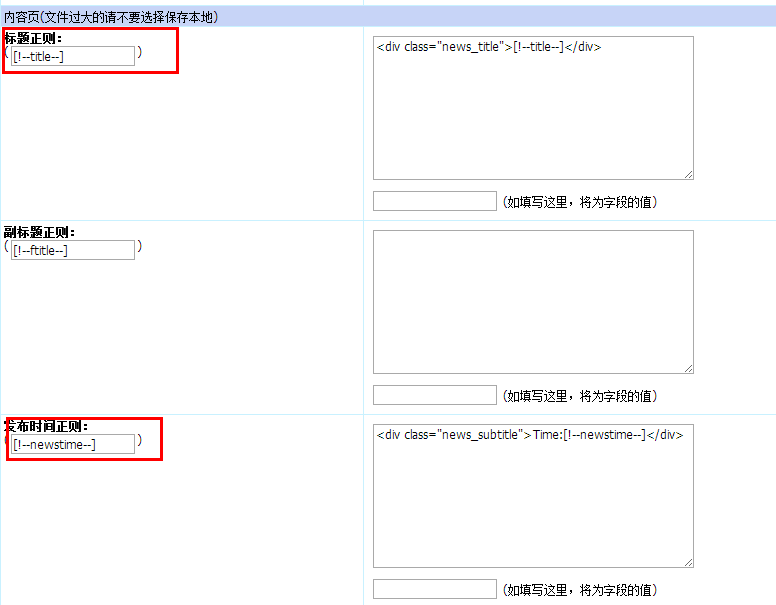
需要注意的是“采集内容正则(不采集项,请留空)” 选项下,对“内容页”选项下的几个正则输入框的填写。查看要采集的页面的源代码,把要采集的地方提取出来,填入相应的正则输入框内。
4、接下来就是开始采集了;

选择左侧“采集管理”-“管理采集节点”,点击“开始采集”。接下来就是等待采集。
采集完后显示本地临时入库的信息,预览如果没有问题的话就可以点击“入库全部信息”按钮,这样采集到的信息就全部录入进了选择的采集栏目中了。